Star Schema and Spotlight
The Spotlight Statistics Repository is based on a star schema because of the simplicity it offers for data storage and retrieval. Star schemas are a simple schema consisting of a centralized fact table connected to multiple dimension tables.
Fact tables hold factual data and the dimension tables hold descriptive data. One of the benefits of a star schema is the speed of data retrieval. With star schemas, you can use relatively simple SQL queries to return particular information about, in this case, a SQL Server instance.
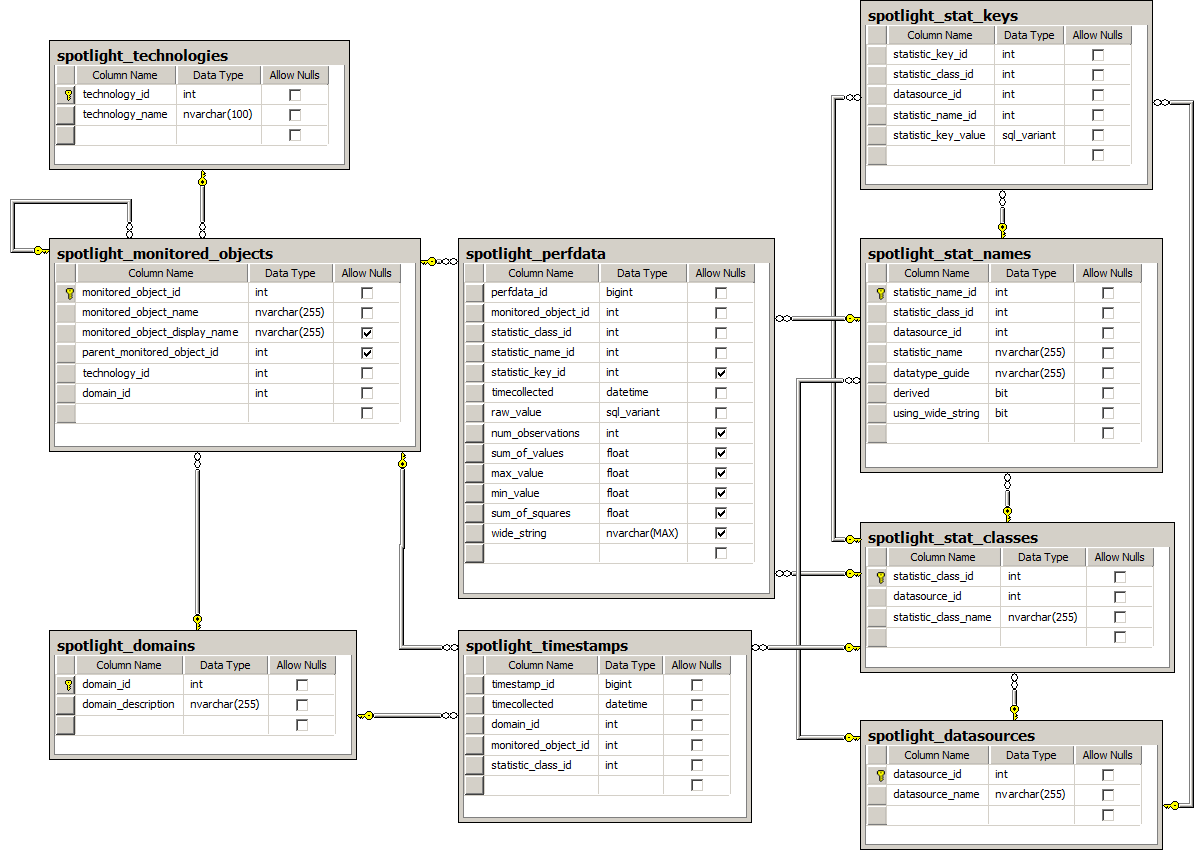
The Spotlight Statistics Repository schema
In the Spotlight Statistics Repository, the fact table (spotlight_perfdata) stores facts related to SQL Server performance, and the dimension tables hold definition data such as SQL Server instance information and attributes.
About the tables
The main dimension tables in the Spotlight Statistics Repository are as follows.
| Table | Description |
|---|---|
| Spotlight_datasources | Contains data used to categorize the collections that are performed by Spotlight. There is one row in this table for each category of data collected. Examples of categories are SQL Server, Windows, and Diagnostic Server. |
| Spotlight_domains | Contains data about the Diagnostic Servers feeding the Spotlight Statistics Repository. In the case of multiple Diagnostic Servers feeding the Spotlight Statistics Repository, there is one row per Diagnostic Server. The Domain_description column contains the Diagnostic Server host name. |
| Spotlight_monitored_objects | Contains data about each of the SQL Server or Windows servers that a Diagnostic Server is monitoring. There is one row in this table for each server being monitored by each Diagnostic Server. |
| Spotlight_techonologies | Contains data that categorizes the collections that are performed. There is one row in this table for each category of data collected. |
The remaining dimension tables contain data about the collections being stored in the Spotlight Statistics Repository.
For more information on all the tables created by Spotlight in the Spotlight Statistics Repository, see [Table Definitions][enterprise_ssrquery_tables].